We process 40-45K cards every day.
At Collectors, we usher tens of thousands of cards through our grading operation everyday. Before the cards hit the grading room, they need to be properly identified. Identification is a time consuming part of our process, and requires a person to manually enter the name, type, and year that identifies each card. We use text-based search engines which shorten the amount of time that our research team spends identifying cards. However, we know there are more ways to enhance the speed and accuracy at which our teams are able to complete this step. This got my team thinking,
Is there a better way to identify cards more accurately while also being more time effective?
First, let me introduce myself before diving into how I answered these questions. My name is Imir Kalkanci and I have been working at Collectors for the last 7 years. I joined the company with the collectors.com project, where I helped to develop a search engine that aggregates millions of collectible items from various sources. Most recently, I’ve been focusing on computer vision and scalable image management solutions.
A couple of years ago, I started working on a new project to answer the above question. My hypothesis was that we could use card images to create a reverse image search engine, similar to Google and TinEye reverse image searches. This engine would allow users to search for images using the image as the starting point, rather than a written search query. We further postulated that we would be able to automate the process and assign other metadata to the card before the research team even laid eyes on it.
Early implementation
Since our grading process requires exact matches, I attempted to use an image hashing algorithm. Image hashing is a technique that converts an image to a fixed-size alphanumeric data element. I calculated hash values of sample images using a perceptual hash library (pHash), and I was then able to test how these matched with query images. I found that this method is relatively fast and performs well for finding resized images. However, other transformations like brightness or rotation lead to poor performance. With this knowledge, I iterated and reattacked.
For my second approach, I used more traditional computer vision based algorithms to find visual features of the cards. Methods I tried included Scale-Invariant Feature Transform (SIFT), Speeded Up Robust Features (SURF), and Oriented FAST and Rotated BRIEF (ORB). I would then compare detected numbers that were common between the two images. The ORB keypoint detector felt increasingly promising as I spent more time learning and iterating. It is intended to be rotation invariant and deals well with noise and was also much faster than other feature descriptors. I generated a database from extracted keypoints and compared query images by calculating their distance. Unfortunately, with the growing number of data, the quality of the search result decreased. Selecting meaningful and strongest keypoints started becoming a challenge I did not originally anticipate. Cards that featured heavy text or busy imaging had increasingly poor results.
 An example output of keypoints (light blue dots), without size or orientation, detected using the ORB library in OpenCV.
An example output of keypoints (light blue dots), without size or orientation, detected using the ORB library in OpenCV.
Card: 1986 Fleer Michael Jordan
Fail fast and iterate
At this point, I was excited because a byproduct of my discovery was more deeply understanding the main concept of machine learning.
After discovering many solutions that weren’t optimal, I remained unphased and looked for alternative approaches! I realized that a convolutional neural network (CNN) could be the answer I was looking for. Beginning with image classification models, I selected a couple of categories and trained a network. Search results were also very good within this small dataset. The main drawback I saw was that labeling thousands of cards and finding a lot of images for the training wasn’t scalable. This was a sad finding in a project where speed, accuracy, and scalability were the success criteria.
After a little more research, I discovered one of the operations in this method converts input images into feature vectors. They are basically collections of a few thousand floating-point values and contain the most important and noticeable components of the images. Now this is something we definitely can use! I began extracting image features from using pre-trained models of CNN and created a database that allows me to run approximate nearest neighbor searches in high dimensional space.
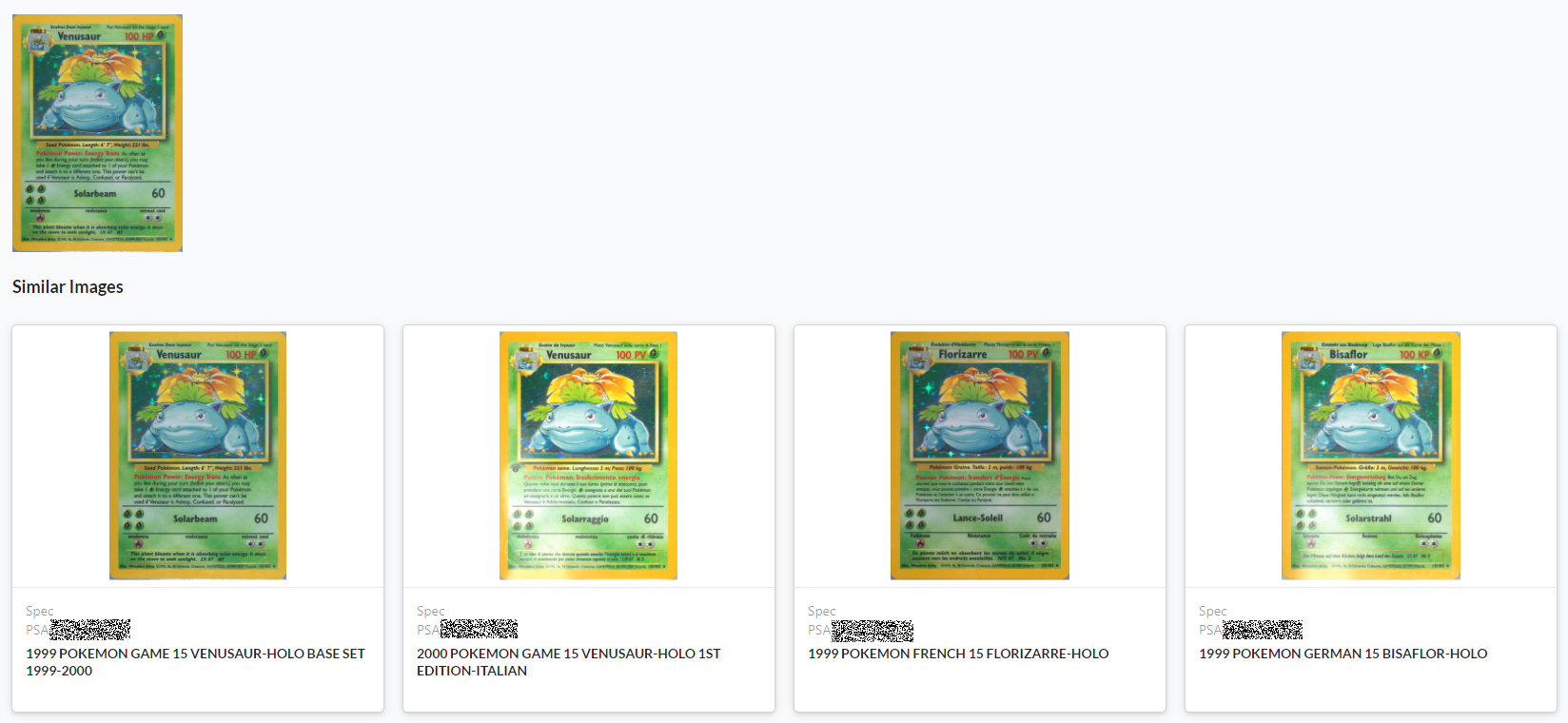
Our CNN-powered image search displaying the card and potential matches.
Card: 1999 Pokemon Game 15 Venusaur-Holo Base Set
Today, the image search engine helps our research team identify all types of cards easily, accurately, and efficiently. Moving forward, I see a ton of opportunities to enhance counterfeit and error detection with growing numbers of data. While the solution currently assists our internal teams, we’re excited to scale it and provide these benefits to our customers.
Personally, this project helped me to work in different areas that I’m not familiar with. I had the opportunity to learn new techniques and tools that scale up the business to the next level.


