We’re buried in coins. It’s a good problem to have, but all the same, we’re buried in coins. From Coin Facts, to Pop Report, to our Online Submission Center, there is so much software on the PCGS side that no single person can climb high enough to get a birds-eye view. Once they scale one stack, they slide down into another. That’s a great problem to have, it means we’re a treasure trove! It also means we have a great opportunity to improve discoverability, maintainability, and quality assurance (QA). In this article, we’ll explore pain points with our legacy API patterns, define constraints to address each one, and present our new solution.
For context, we have a robust ecosystem of legacy applications, many supported by shared libraries. While these libraries provide a powerful mechanism for reusing logic, it can be very difficult to answer the question: “Which systems are using which libraries?.” Let me draw you a picture.
PCGS Legacy App Ecosystem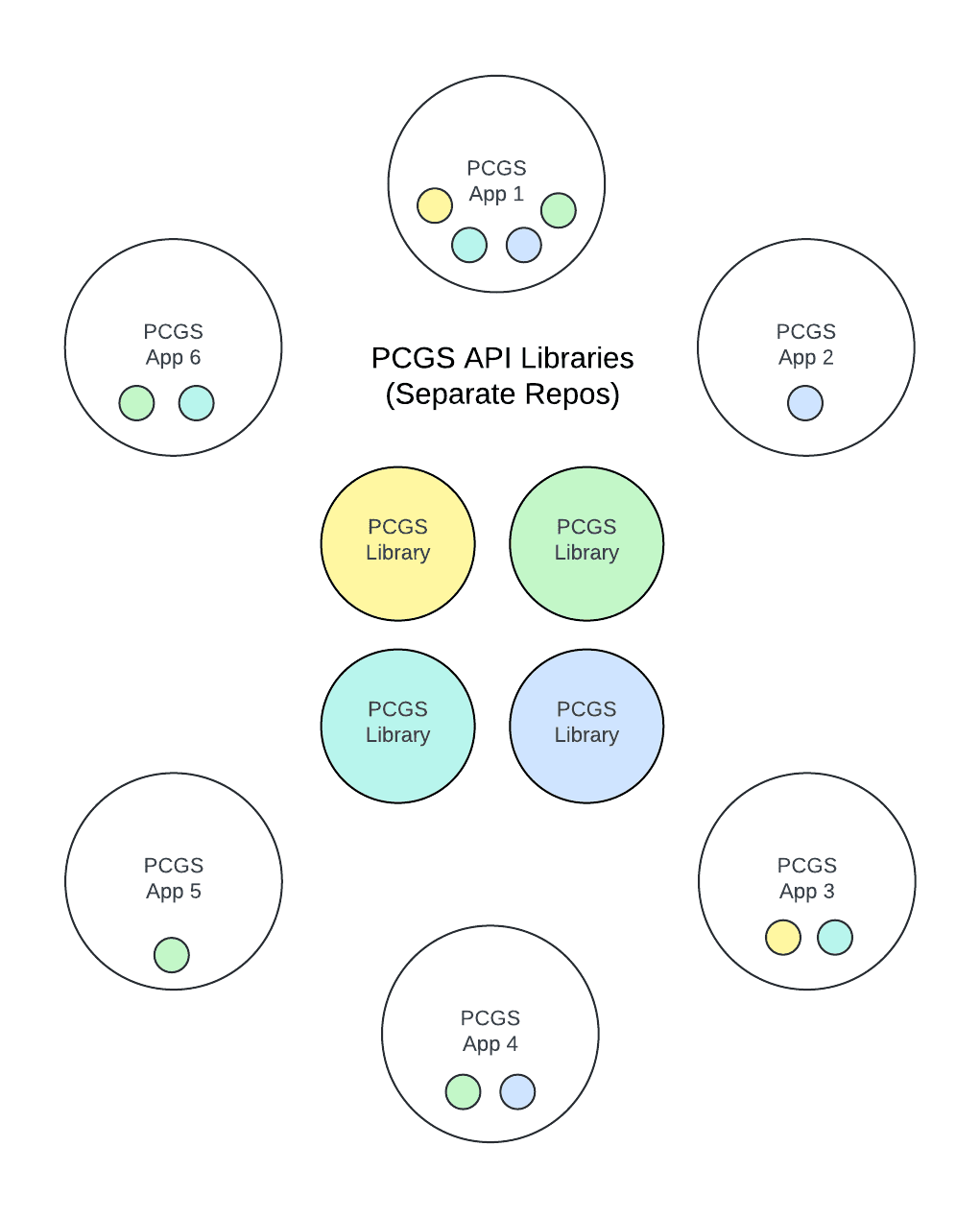
In the center of the picture, we have our shared libraries, where each library lives in its own repository (or repo if you’re cool). Orbiting around them are apps, which also live in their own repos. Each app uses one or more shared libraries, drawn as color-coded dots.
To understand which apps depend on which libraries, we must search across 10+ repositories. That’s a lot of time! Now imagine this is your ecosystem, pain points and all.
Pain Point: Discoverability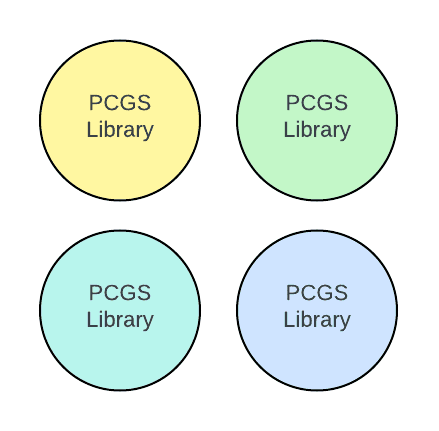
Suppose you’re tasked with modifying one or more libraries and someone asks “Which apps will this affect?” Here’s your view of the world from the library perspective:
…You absolutely can’t answer that question. You can’t see the apps! You’d need to hunt for an unknown number of other repositories, searching for connection strings, URL references, and import statements. You’d have to read TypeScript, Java, .NET, Python, and multiple frameworks. It’d be a long time before you’re actually implementing that new feature that all your amazing customers are asking for.
Pain Point: Maintainability
While it’s difficult enough to tell which apps are using which libraries, it can be just as hard to tell what library versions are being used and to update them. When updating a library, you might need to manually drop a build file in a few places, update a package manager, or sometimes both. If your task involves config file changes, that’s an added layer of discovery and iteration. Reproducing these different configurations for local development can be just as time-consuming as the initial discovery. Now you’re really REALLY not getting to that new feature all your customers are scaling your building and tapping on your window for.
Pain Point: QA
With so many repos, you’re likely dealing with dozens of different build pipelines across multiple testing environments. If you’re like PCGS, you have a wonderful team of skilled QA engineers who rely on consistent testing environments and pipelines. Each new pipeline you introduce adds a burden to the QA process. Worse yet, if multiple apps rely on the same shared library, you need to do integration testing on each of them. This is especially tricky if you can’t properly control the promotion of these features through your environments.
Design Constraints
Presented with these pain points, the PCGS Team set out to completely redesign our backend infrastructure. For each pain point, we defined a design constraint:
- Discoverability: Provide a dedicated API for each app and make sure it’s namespaced for the domain. For example, the “/pcgs/osc/v1” namespace supports the PCGS Online Submission Center (OSC) frontend.
- Maintainability: Implement all APIs within a single repository, but allow them to reference shared logic that can be easily broken out into a single versioned library. All apps will integrate via API, with no drop-in libraries or package managers.
- QA: Promote each API in its own pipeline to our development, QA, and production environments.
PCGS App API Repo
For our implementation, we created the PCGS App API repository, which looks a bit like this: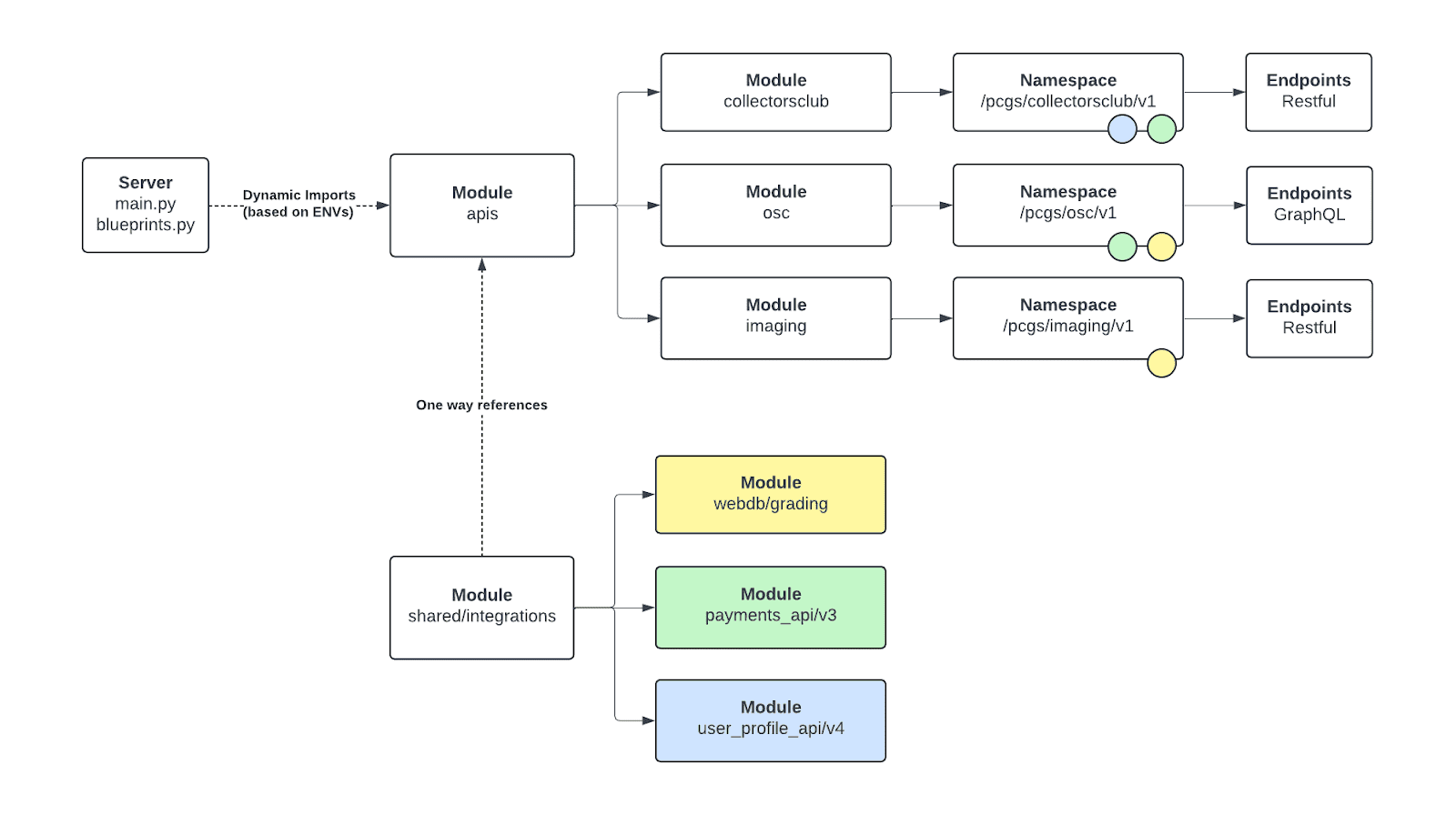
Here we have a single Python repo with multiple modules, one for every API. In addition, we have a “shared” module that acts like a library. This folder contains logic that used to live in our multiple shared libraries and tends to be used across multiple APIs. Here’s another view of the same repo, organized like our legacy library diagram:
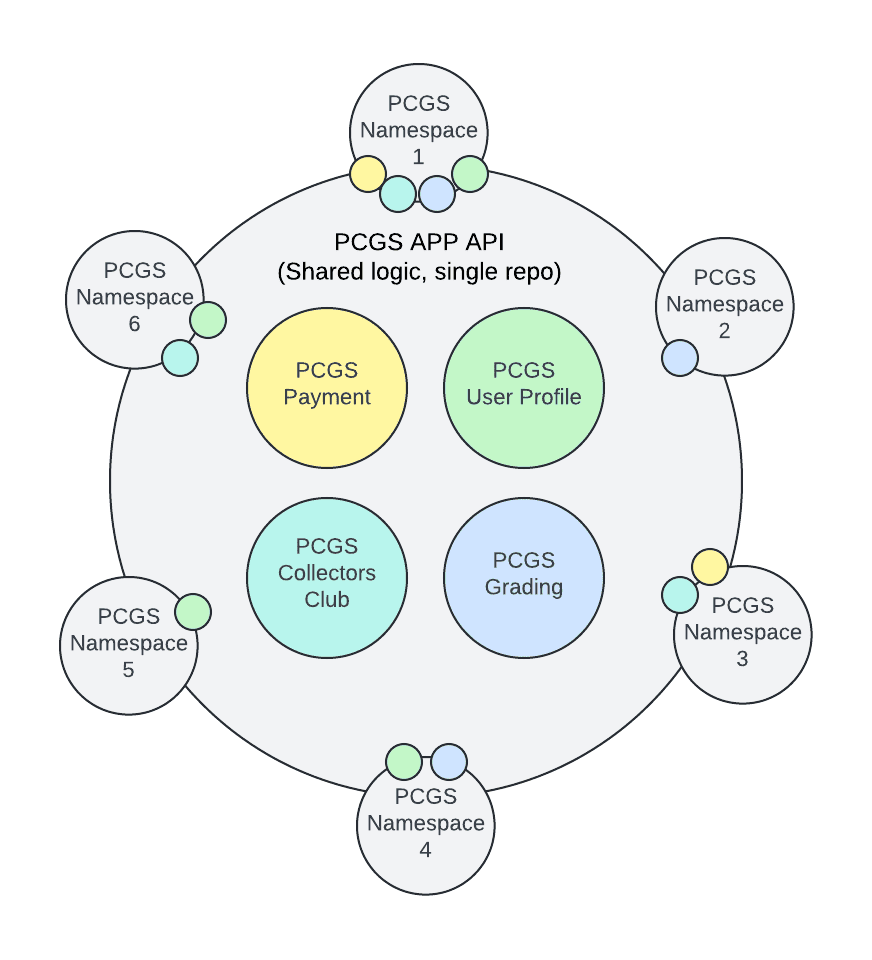
All endpoints are namespaced based on the app consuming them. Now we can answer the question “Which apps will this change affect?” in moments! For instance, if updating payment logic, we can see apps 1 and 3 would be affected. If updating grading logic, that would impact apps 1, 2, and 4. Neat! As a bonus, since the endpoint code and shared logic are all in one repo, our single code editor can lint and validate across multiple APIs in real-time. It is now quite safe and easy to implement that new feature that customers are being airlifted on top of your building and trying to break down the rooftop door for!
Shared Logic
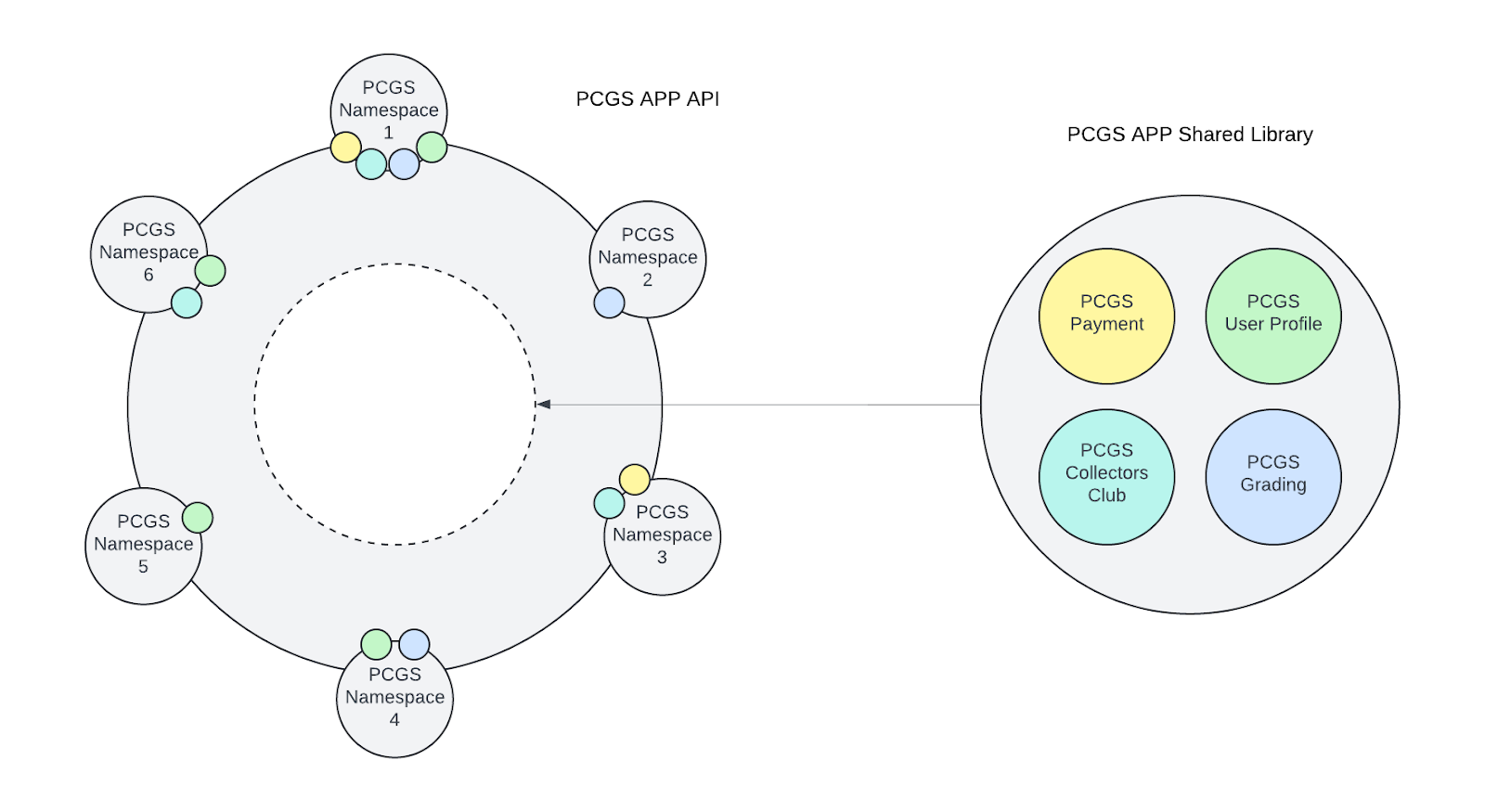
For our initial design, we’re opting to keep all our shared logic in a single folder that has no references outside of itself. As our use case grows, this will make it easy to eventually pull the shared folder out of this repo and turn it into a versioned Python package. However, until this added layer of complexity is needed, we’re really enjoying the benefits of single repo validation and unit tests. Once our use case calls for it, we can just cut and paste the shared folder into its own repo and slap a version on it.
Dynamic Configuration & Pipelines
While we use a single repo, we use declarative environment variables to control which endpoints are activated at runtime. In this way, we can build a single docker container to run our APIs and enable/disable features as needed. This is great for local development because it allows us to run a single debuggable server with all endpoints enabled. Then, during QA we can deploy each of these as separate servers, one namespace per server. This allows us to reuse the same boilerplate for running the server and building our containers.
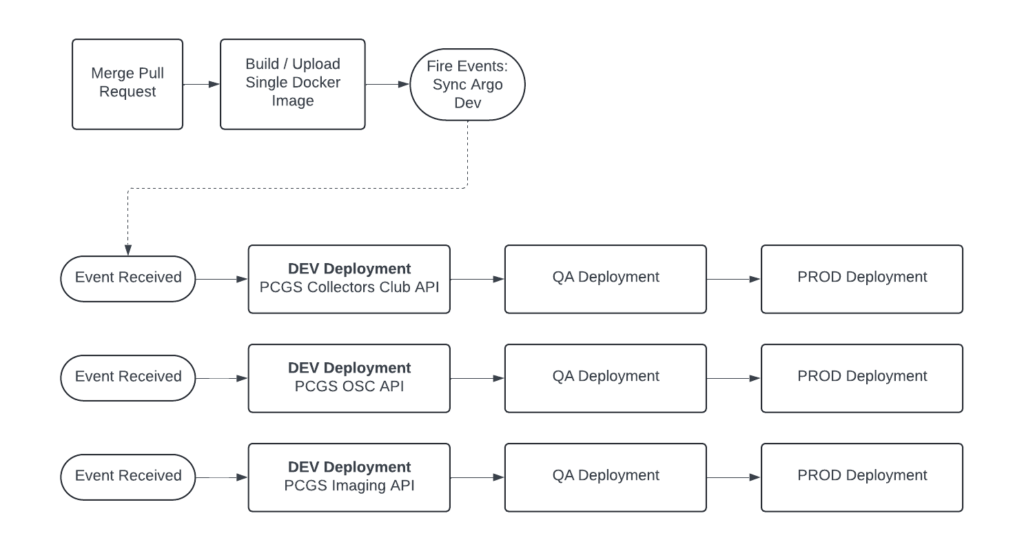
Collectors has a mature Kubernetes (K8s) cluster with multiple GitHub workflow integrations. We’re taking full advantage of it! We use trunk-based development, where merging code into our main branch triggers a single workflow that builds our container. Our apps are then deployed to K8s which has separate environments for development, QA, and production.
In our case, merging a PR causes a single container to build and deploy to EC2. We then fire off one GitHub event for each namespace which triggers our deployments. Once deployed, each namespace can be promoted separately to QA and production. This gives our QA engineers the control they need to test and promote each experience independently.
Benefit Summary
Circling back around to our design constraints, let’s summarize the benefits:
- Discoverability: Our API code now lives in a single repo which contains all the context for which apps are consuming which endpoints. Developers only need to be familiar with a single codebase to answer most questions.
- Maintainability: Our single repo makes it easy to see how changes to shared code will affect multiple apps, and we get instant development feedback when making breaking changes. We no longer use a library pattern, all apps will integrate via API, meaning we don’t need to update configurations, package managers, or manually drop in code.
- QA: Our APIs are deployed as separate K8s deployments across multiple environments allowing our QA engineers to validate features as they see fit. We control what code is running by using environment variables and strive for environments and pipelines to be as consistent across all APIs as possible.
The PCGS Team arrived at these design conclusions by starting with our pain points and solving each one by one. However, in retrospect, we’ve discovered the pattern we’re using is very closely aligned with the 12 Factor App methodology. If you’ve never heard of it, I encourage you to look that up and compare for yourself!
With the PCGS App API pattern, we’ve taken our toppling piles and turned them into a carefully curated collection. We’re now ready for more coins!


